
Will ‘IPv8’ Ever Arrive? Expectations for Next-Generation Internet Protocols
People sometimes say, “IPv4 was followed by IPv6, so maybe IPv8 is next.” In practice, though, there is no formal standard called IPv8. The version field in IPv4 is 4 bits wide, so values from 0 to 15 are theoretically possible. IPv5 was already used by the Internet Stream Protocol (ST) in 1979, and IPv6 was deliberately designed as a clean break from IPv4. There have been scattered proposals for IPv7 and beyond, but nothing after IPv6 has been standardized by the IETF.
So what is actually being researched and standardized as the next generation of Internet protocols? And how are those efforts trying to address the limits of IPv4? This article looks at the current state of play.
IPv4 Is Still Here, but the Pain Points Keep Growing
Start with the obvious fact: IANA ran out of unallocated IPv4 space back in 2011. In day-to-day operations, though, IPv4 is still kept alive by NAT, CGNAT, CDNs, proxies, and the address transfer market.
IPv6 adoption rates still vary widely from country to country.
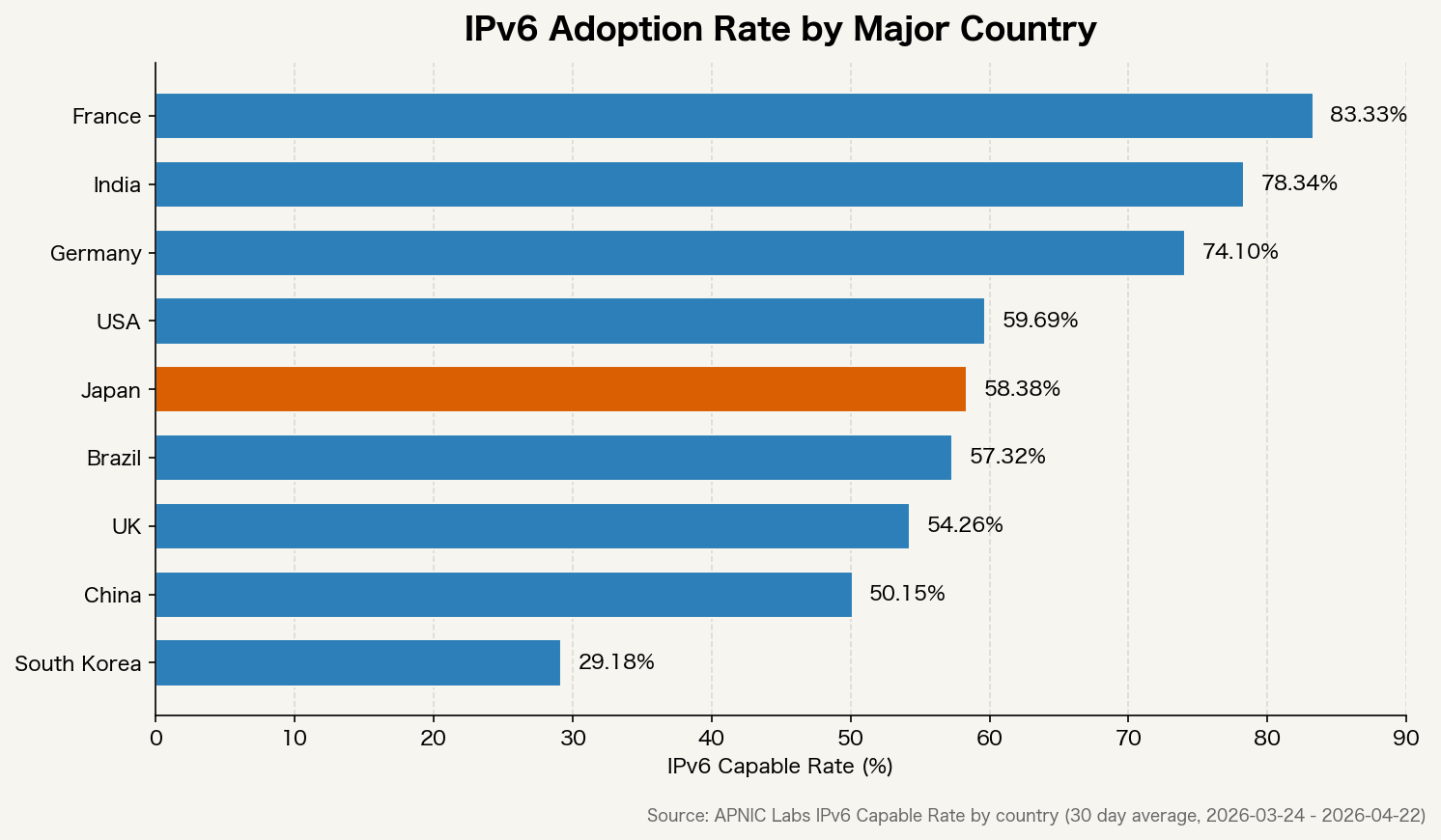
France and India are already in roughly the 70 to 90 percent range, while Japan and South Korea are still below 50 percent. The reason IPv6 rollout remains slow is not that the standard itself is broken. The real issue is that NAT still works well enough to postpone migration, so the business priority often stays low.
Fixed broadband speeds also differ sharply across countries.
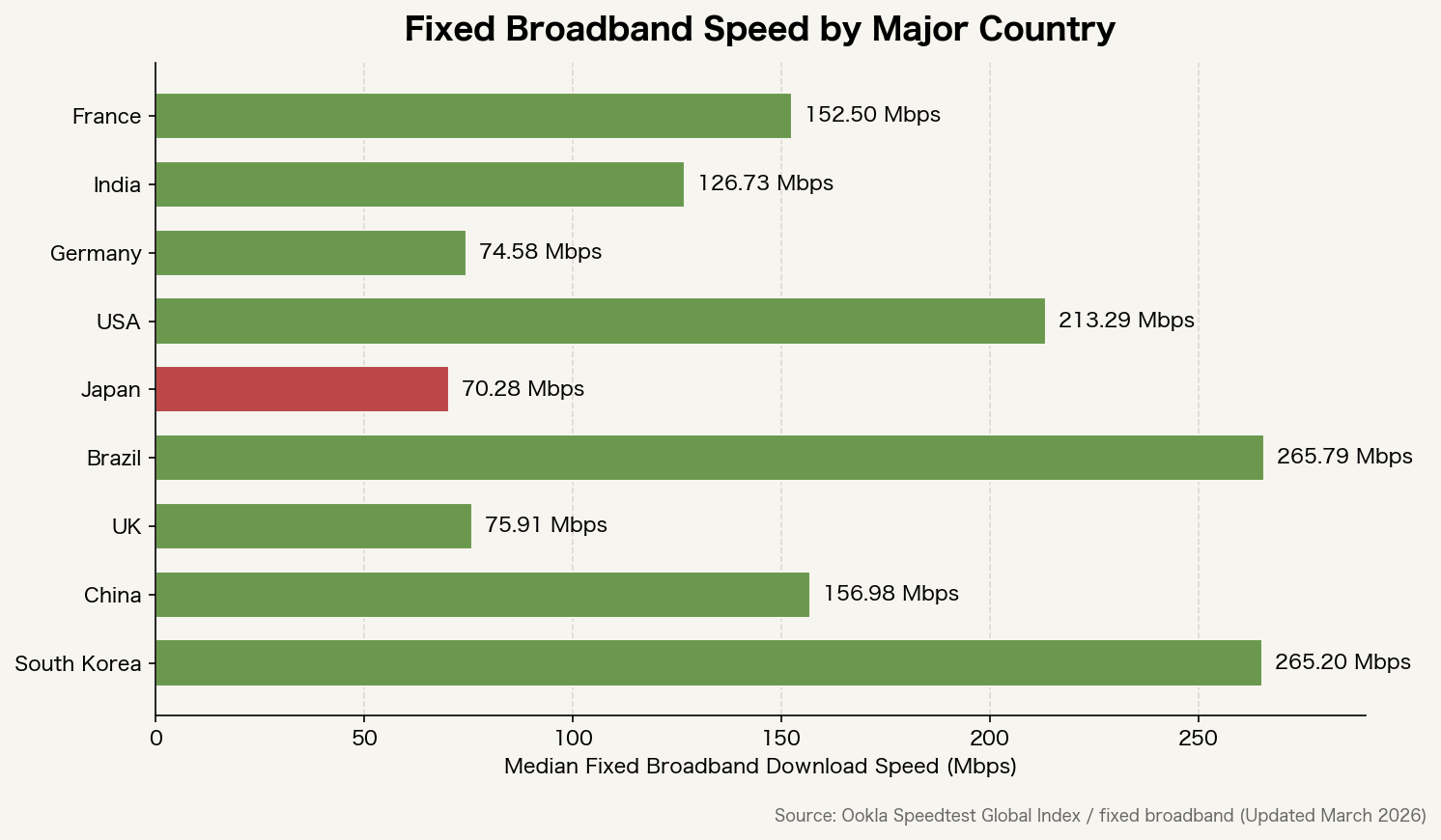
Infrastructure investment is still the biggest factor, but extra NAT and proxy layers also add latency. The more patches are applied to stretch the life of IPv4, the more network paths lose their simplicity.
Why IPv6 Chose a Clean Break, and What That Cost
IPv6 gave up backward compatibility with IPv4 on purpose. The goal was not just to expand the address space from 32 bits to 128 bits, but also to redesign the header format and move back toward an end-to-end model that does not assume NAT.
That clean break, however, also made migration expensive. The long dual-stack era forced organizations to manage monitoring, firewalls, log analysis, and allowlists twice. Costs went up, but the end-user benefit remained hard to see, so many teams concluded there was no compelling reason to move immediately.
That experience naturally led to a different question: could the network be extended without throwing away compatibility with IPv4? That line of thinking is what led to SRv6 and a range of transition technologies.
SRv6: Extending IPv6 While Carrying IPv4
SRv6 (Segment Routing over IPv6) uses IPv6 extension headers to make packet paths explicit. It was standardized in RFC 8986.
What matters here is that IPv4 packets can be encapsulated inside SRv6. In other words, IPv4 traffic can be carried over an IPv6-based path-control model. It is one of the closest things we currently have to an IPv4-friendly upgrade path built on top of IPv6.
SRv6 is attractive because it can address several operational problems at once.
- Path control without MPLS labels, which reduces label-stack complexity
- Finer-grained traffic engineering on a per-path basis
- More consistent path control across cloud and carrier network boundaries
- A single forwarding plane for mixed IPv4 and IPv6 environments
NTT, China Telecom, and Alibaba are already moving toward commercial deployment, especially between large-scale data centers and in 5G core networks.
SCION: Redesigning the Path Itself
While SRv6 extends IPv6, SCION (Scalability, Control, and Isolation On Next-generation networks) aims at something more radical: redesigning the path model itself. The project was led by ETH Zurich and introduced in IEEE Security & Privacy 2011.
The core idea behind SCION is simple: route choice should belong to the sender. On the Internet today, paths are determined by BGP (Border Gateway Protocol), and the sender has little direct control over which route traffic takes. In SCION, the sender can explicitly choose the path.
That has several implications.
- It makes route hijacking and arbitrary path manipulation harder
- It lets the sender choose paths based on latency, bandwidth, or reliability
- It helps contain failures within a narrower set of autonomous systems
- Authentication is built into the architecture, making spoofing more difficult
SCION is already used in production by the Swiss Secure Finance Network (SSFN). Because it can run as an overlay on top of IPv4 and IPv6, it can coexist with today’s infrastructure.
NDN: Routing by Content Name Instead of IP Address
NDN (Named Data Networking) routes traffic by content name rather than host address. It has been studied as part of the Future Internet Architecture project supported by the NSF.
Today’s Internet is built around the question, “Which host am I sending to?” NDN changes that to, “What content do I want?” Content is named, and routing follows that name.
That could solve several things.
- The network itself can cache identical content, enabling CDN-like behavior at the infrastructure layer
- Content integrity becomes easier to verify because verification can be tied to the content name
- Mobility becomes smoother because communication is no longer anchored to the sender’s IP address
The downside is weak compatibility with the installed IP base, so broad adoption remains uncertain. For now, the more realistic use cases are in IoT and edge computing.
QUIC/HTTP3: Hiding IP-Version Differences at a Higher Layer
There is also a more pragmatic direction: do not replace the network architecture at all, and instead absorb IPv4/IPv6 differences at a higher layer. QUIC (RFC 9000) is the clearest example.
QUIC runs over UDP and does not rely directly on the IP address and port pair as the connection identifier. Instead, it uses a connection ID. That allows the connection to survive even when the underlying IP address changes.
In practice, that means upper-layer behavior can remain consistent whether the transport is running over IPv4 or IPv6. HTTP/3 builds on QUIC, and support is now widespread across major browsers and servers.
How Close Are We to an “IPv4-Compatible Upgrade Path”?
The most practical approach today is probably the combination of SRv6 and transition technologies such as MAP-T.
MAP-T (Mapping of Address and Port using Translation, RFC 7599) carries IPv4 packets across an IPv6 network and restores them to IPv4 at the edge. Endpoints stay on IPv4 while the backbone migrates to IPv6.
In combination, that allows an architecture where:
- End users continue using IPv4
- The core network is built around IPv6
- Path control is unified under SRv6
That is already workable in practice. A brand-new protocol version called “IPv8” is not strictly necessary to get most of the way there.
What Is Already Happening in the Real World
It is worth separating real deployments from speculation.
- 5G SA (Standalone): IPv6 is already the design assumption for the core network under 3GPP standards
- Commercial SRv6 rollouts: China Telecom, NTT, and SoftBank are introducing it into backbone networks
- SCION in production: already running in Switzerland’s financial network (SSFN)
- Apple App Store review: apps are required to work in IPv6-only environments
- Cloudflare / Google: IPv6 traffic keeps rising, while edge architectures increasingly absorb the differences between IPv4 and IPv6
The next phase of Internet protocol evolution is not arriving as one clean replacement. It is emerging as a layer-by-layer shift.
The practical step right now is to reduce dependence on raw IP addresses wherever possible. Move away from fixed-IP allowlists when you can. Shift toward certificate- and identity-based authentication. Use DNS properly. Lean on CDNs and edge architectures. Those are the kinds of design choices that make a system more resilient no matter which protocol model wins out.
My View: It Might Have Been Better to Extend IPv4 to Eight Octets
My personal view is straightforward.
When you look at the fact that IPv6 chose a clean break and the transition is still incomplete nearly thirty years later, it is hard not to wonder whether the design trade-off was the right one.
The model I find most compelling is simple: keep IPv4-style notation, but extend it to eight octets.
255.255.255.255.255.255.255.255
In other words, take the current x.x.x.x (32-bit) format and extend it into x.x.x.x.x.x.x.x (64-bit).
What would that have changed?
The address space would have expanded dramatically
IPv4 gives us roughly 4.3 billion addresses. At 64 bits, that jumps to about 18.4 quintillion. Even in a world with tens of billions of IoT devices, the address pool would be vast enough that NAT-based extension would be far less necessary.
Backward compatibility with IPv4 would have been easier to preserve
If existing IPv4 addresses had simply been represented as 0.0.0.0.x.x.x.x, then current IPv4 packets could have worked as a subset of the new model. Routers could have treated any address with upper four octets of 0.0.0.0 as IPv4-compatible. That alone might have shortened the ugly dual-stack period considerably.
Human-readable notation could have been preserved
An IPv6 address such as 2001:0db8:85a3:0000:0000:8a2e:0370:7334 is awkward to work with during incident response, log review, and firewall rule maintenance. With an eight-octet format, anyone comfortable with IPv4 could still parse it quickly.
# Current IPv4
192.168.1.100
# Proposed 8-octet extension
0.0.0.0.192.168.1.100 (IPv4-compatible space)
10.48.0.0.192.168.1.100 (example of a new global address space)
It might also have offered operational security advantages over IPv6
The advantage here would not have been stronger cryptography or better authentication by default. The advantage would have been operational. If IPv4 compatibility had been preserved, existing firewall rules, IP allowlists, SIEM correlation logic, and address-based settings in WAF and VPN appliances could have been reused much more easily. It also might have reduced the length of time organizations had to maintain separate IPv4 and IPv6 rule sets side by side.
IPv6 addresses are longer and support multiple compression forms, which makes human review, audits, and troubleshooting more error-prone. An eight-octet model would have kept logs, allowlists, and incident triage much closer to the IPv4 operational experience. In environments like Japanese enterprise systems, where fixed-IP allowlisting is still common, that might have reduced operational security overhead compared with IPv6.
There are practical drawbacks, of course
This still would not have been a perfect design.
- Even 64 bits may not be enough for a far-future world of massive IoT and AI-agent networks, which is one reason IPv6 chose 128 bits
- Routers would still have needed changes in address-processing logic, which would have been a heavy ask for 1990s hardware
- Expanding the address format alone does not solve authentication or cryptographic security
Even so, “keep the notation and just add more octets” still feels like a plausible real-world alternative when you weigh it against the migration cost that IPv6 has imposed over the last three decades.
The designers of IPv6 clearly understood that trade-off and still chose the clean break. Even so, the fact remains that a large share of the world still runs on IPv4 today.
My View: NAT Bottlenecks Are Also a Physical-Layer Problem
There is one more angle that deserves attention.
NAT becomes a bottleneck not only because translation itself costs CPU cycles. Today’s network equipment also converts incoming optical signals into electrical ones before processing them. That electrical domain introduces heat, interference, and signal degradation. NAT processing happens there as well, so its limits become increasingly visible at large session counts.
NTT’s IOWN (Innovative Optical and Wireless Network) initiative, together with the APN (All-Photonics Network) at its core, is trying to rethink that structure from the ground up.
The conventional model looks like this.
Optical fiber -> [electrical conversion] -> router (electrical processing) -> [optical conversion] -> optical fiber
APN is aiming for something closer to this.
Optical fiber -> router (processed optically) -> optical fiber
The idea is to create end-to-end optical wavelength paths and forward or control packets without converting them back into electricity. IOWN also looks beyond the network layer toward devices and semiconductors themselves. NTT has cited goals such as 1/100 power consumption, 125x transmission capacity, and 1/200 end-to-end latency relative to current architectures.
What changes if that becomes practical?
The processing cost of NAT could fall at the root
If electrical conversion disappears, so do much of the delay and heat that come with it. The session-scale limits faced by CGNAT could ease significantly. That suggests that what people often describe as “NAT is slow” is not just a protocol issue, but partly a physical-layer one.
IPv4 could survive even longer
Paradoxically, widespread APN could extend the life of the “NAT is still good enough” world. But by easing the processing bottleneck, it would also let operators handle more devices with fewer boxes. Power consumption would fall sharply, changing the economics of infrastructure operations.
The next real breakthrough may come from an entirely different direction
The debate over IPv4 versus IPv6, or eight octets versus 128 bits, is fundamentally about addressing and path control. IOWN/APN introduces a different axis altogether: physical transport speed, power efficiency, and latency.
Protocol design and physical infrastructure evolve on separate timelines. If APN creates a foundation that can handle any protocol at high speed and low latency, then whether the future belongs to IPv4, IPv6, or something else, the practical range of choices becomes wider.
NTT is targeting commercialization in the 2030s, so this remains in the research and proof-of-concept stage for now. Even so, the idea of processing optical signals without converting them back into electricity could reshape the physical foundation of the Internet. It is well worth watching alongside the protocol debate itself.